on
Phân nhóm các thuật toán Machine Learning
Có hai cách phổ biến phân nhóm các thuật toán Machine Learning.
Một là dựa trên phương thức học (learning style) Hai là dựa trên sự tương đồng về chức năng của mỗi thuật toán (similarity)
1. Phân nhóm dựa trên phương thức học
Theo phương thức học, các thuật toán thường được chia làm 4 nhóm: Supervised Learning (Học có giám sát), Unsupervised Learning (Học không có giám sát), Semi-supervised Learning (Học bán giám sát), Reinforcement Learning (Học tăng cường).
Nhưng nhìn chung, Học máy có hai nhóm chính là Supervised Learning và Unsupervised Learning
1.1 Supervised Learning
Học có giám sát hay học có thầy là thuật toán dự đoán đầu ra hoặc nhãn (label) của một dữ liệu mới dựa trên dữ liệu đã huấn luyện.
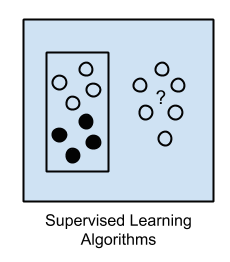
Một mô hình được xây dựng và huấn luyện để đưa ra các dự đoán, nếu dự đoán bị sai hoặc mức độ chính xác (accuracy) không cao, sẽ được tinh chỉnh lại. Điều này giống như việc ta học với giáo viên trên lớp, giáo viên sẽ dạy ta những kiến thức với những đáp án chính xác về vấn đề nào đó ( dữ liệu có nhãn) và từ đó đối với những bài toán tương tự, ta sẽ dựa vào kiến thức đã học được để giải quyết và sữa chữa nếu làm sai.
Ví dụ: Bài toán kinh điển về dự đoán giá nhà đất với dữ liệu là diện tích, số phòng ngủ, số tầng, thời gian xây dựng, và quan trọng nhất là giá nhà (label).
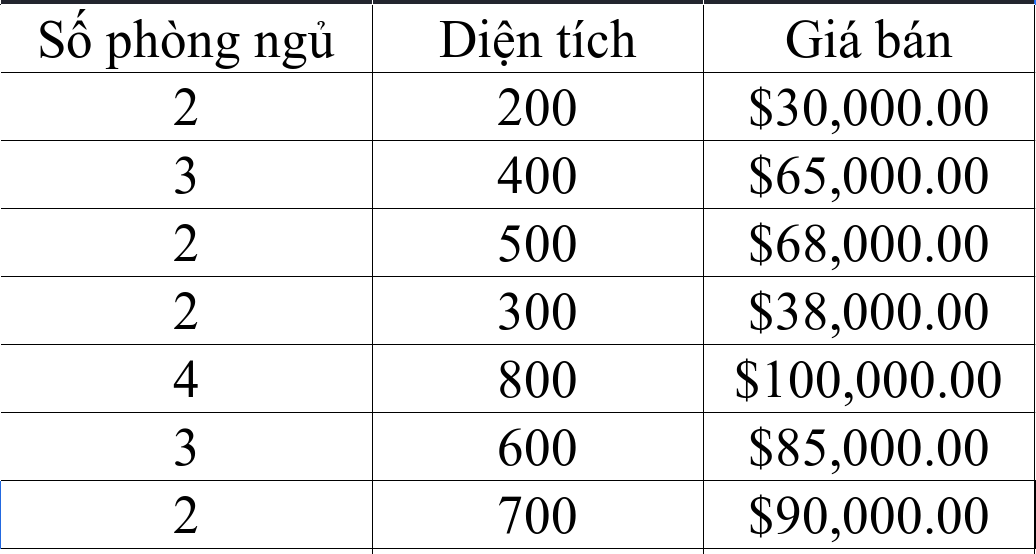
Sử dụng dữ liệu đã cho, xây dựng mô hình Machine learning để ướng tính giá trị của bất kì căn hộ nào khác có dữ liệu tương tự, ví dụ:

Đây là ví dụ về thuật toán Regression (Hồi quy), một trong hai loại chính của Supervised Learning, sẽ nói rõ hơn trong bài viết nào đó ở tương lai.
1.2 Unsupervised Learning
Học không giám sát hay học không có thầy, đối với thuật toán này, dữ liệu đầu vào là những dữ liệu không có nhãn (no label) hay nói cách khác không biết câu trả lời chính xác cho dữ liệu đầu vào. Điều này giống như một đứa trẻ tò mò về thế giới xung quanh, từ những thứ đã thấy và dựa vào những đặc điểm chung, có liên quan tới nhau để đưa ra kết luận.
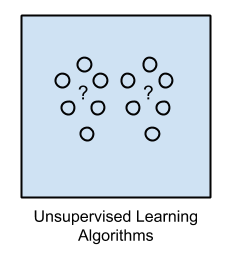
Ở thuật toán này, mục đích không phải là tìm ra đầu ra chính xác mà hướng tới việc tìm ra cấu trúc hoặc đặc điểm, sự tương quan trong dữ liệu để thực hiện công việc nào đó, ví dụ như Clustering (Phân cụm) hoặc Dimention reduction (Giảm chiều dữ liệu) để thuận tiện trong việc lưu trữ và tính toán.
Ví dụ: Phân loại khách hàng dựa vào độ tuổi, giới tính, sở thích mua sắm, tình trạng hôn nhân. Hoặc những hệ thống gợi ý (Recommendation system) dựa vào thói quen mua sắm của khách hàng mà đưa ra những gợi ý nhằm thúc đẩy nhu cầu mua sắm, tăng doanh thu…
1.3 Semi-supervised Learning
Học bán giám sát là thuật toán mà dữ liệu đầu vào là một tập hợp của các dữ liệu có nhãn và không có nhãn, trong đó số lượng có nhãn chỉ chiếm phần nhỏ.
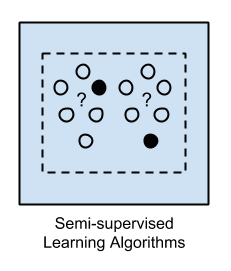
Phần lớn bài toán thực tế của nhóm này là bởi vì việc thu thập dữ liệu có nhãn tốn nhiều thời gian và chi phí, hoặc có những dữ liệu đòi hỏi phải cần tới chuyên gia mới gán nhãn được (ví dụ như dữ liệu y tế về ung thư phổi). Ngược lại, dữ liệu không nhãn lại dễ kiếm và chi phí thấp từ Internet.
Với bài toán này, giống như việc kết hợp giữa hai thuật toán Supervised và Unsupervised Learning vậy. Unsupervised learning để khám phá và tìm hiểu cấu trúc của dữ liệu, Supervised learning để dự đoán cho dữ liệu không có nhãn. Sau đó lại đưa dữ liệu vừa dự đoán trở lại thành dữ liệu huấn luyện cho Supervised learning và sử dụng mô hình hoàn chỉnh để dự đoán dữ liệu mới.
1.4 Reinforcement Learning
Học tăng cường hay học củng cố là bài toán giúp một hệ thống tự động xác định hành vi dựa trên hoàn cảnh để đạt được lợi ích cao nhất (maximizing the performance). Hiện tại thuật toán này được áp dụng nhiều vào Lý thuyết Trò chơi (Game Theory).
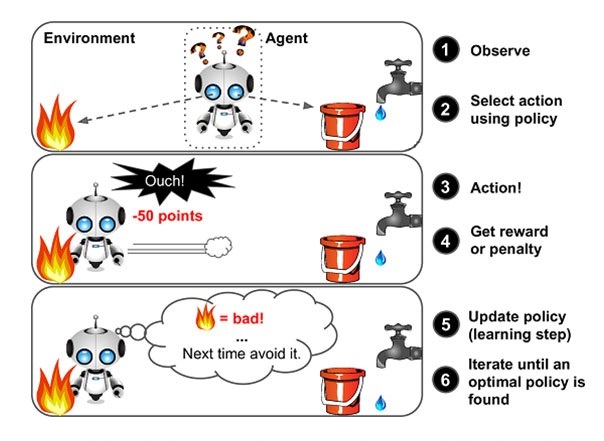
Ví dụ nổi tiếng nhất của thuật toán này là AlphaGo - phần mềm chơi cờ vây được xây dựng bởi Google DeepMind.

AlphaGo sử dụng dữ liệu là những ván cờ con người chơi với nhau để huấn luyện. Tuy nhiên mục đích của AlphaGo không chỉ chơi cờ giống như con người mà chơi thắng cả con người. Do đó, sau khi học xong các ván cờ của con người, AlphaGo tự chơi với chính nó tới hàng triệu ván chơi để tìm ra nước đi tối ưu hơn.
2. Phân nhóm dựa trên sự tương đồng về chức năng
2.1 Regression Algorithms (Thuật toán hồi quy)
Mục tiêu của thuật toán Hồi quy là dự đoán số liên tục (continuous number) hoặc số dấu chấm động (floating-point number) trong thuật ngữ lập trình ( hay số thực trong thuật ngữ toán học). Dự đoán thu nhập hằng năm của một người dựa trên trình độ học vấn, tuổi tác và nơi họ sống cũng là một ví dụ về thuật toán Hồi quy.
Một ví dụ khác là dự đoán năng suất lúa trên một cánh đồng dựa trên các đặc trưng như năng suất của vụ trước, thời tiết, vụ nào trong năm,..
2.2 Classification Algorithms (Thuật toán phân loại)
Mục tiêu của thuật toán phân loại là dự đoán dữ liệu mới thuộc vào nhãn nào trong các nhãn đã có sẵn ở dữ liệu huấn luyện.
Phân loại có thể chia thành phân loại nhị phân (binary classification) và phân loại nhiều lớp (multiclass classification).
Trong đó, phân loại nhị phân chỉ là việc phân loại vào chính xác hai lớp, ví dụ bài toán trả lời câu hỏi yes/no hoặc email này là spam hay not spam. Về phía Multiclass classification thì sẽ có nhiều hơn hai lớp, ví dụ như bài toán phân loại hình tròn, hình vuông, hình tam giác…
Để phân biệt giữa hai thuật toán hồi quy và phân loại, thì thuật toán phân loại sẽ dự đoán dữ liệu mới thuộc vào nhãn nào trong dữ liệu huấn luyện, còn thuật toán hồi quy sẽ đưa ra kết quả mới dựa trên dữ liệu huấn luyện, kết quả có thể là một giá trị cụ thể hoặc là một khoảng giá trị.
2.3 Instance-based Algorithms (Thuật toán dựa trên mẫu)
Những thuật toán này không thể hiện khái quát hóa rõ ràng, thay vào đó nó sẽ so sánh dữ liệu mới với dữ liệu được lưu trữ trong tệp huấn luyện.
Ví dụ thuật toán KNN (k-Nearest Neighbor) không thực hiện tính toán để tìm ra cấu trúc hoặc mối tương quan dữ liệu, thay vào đó nó chỉ thực sự hoạt động khi đưa dữ liệu vào, sau đó thuật toán tiến hành so sánh với các điểm dữ liệu gần với điểm dữ liệu cần dự đoán rồi đưa ra kết quả phù hợp.
2.4 Regularization Algorithms
Regularization là kỹ thuật dùng trong hồi quy để giảm sự phức tạp của mô hình và sự thu nhỏ hệ số của các đặc trưng độc lập
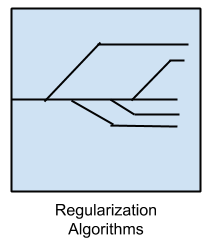
Nói gọn hơn thì kỹ thuật này nhằm biến đổi mô hình phức tạp thành mô hình đơn giản hơn, để tránh rủi ro ‘quá khớp’ (overfitting) và thu nhỏ các hệ số, cho chi phí tính toán thấp hơn.
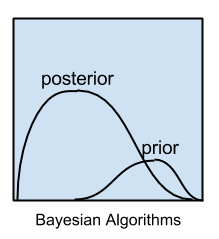
2.5 Bayesian Algorithms (Thuật toán Bayes)
Là nhóm thuật toán áp dụng định lý Bayes cho bài toán phân loại và hồi quy.
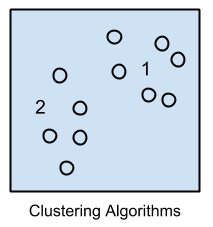
2.6 Clustering Algorithms (Thuật toán Phân cụm)
Thuật toán phân cụm liên quan tới việc phân nhóm dữ liệu, chia các điểm dữ liệu vào các nhóm theo sự tương đồng về các thuộc tính hoặc đặc trưng (feature), các điểm dữ liệu ở các nhóm khác nhau có sự khác nhau nhất định. Là thuật toán của Unsupervised learning.
2.7 Artificial Neural Network Algorithms (Thuật toán mạng nơ rôn nhân tạo)
Thuật toán này thiết kế mô hình lấy cảm hứng từ cấu trúc của mạng lưới thần kinh sinh học.
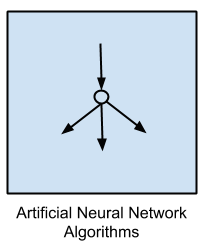
Nhóm thuật toán này có thể sử dụng cho bài toán phân lớp và hồi quy với nhiều bieesnt hể khác nhau cho hầu hết các vấn đề.
2.8 Dimensionality Reduction Algorithms (Thuật toán giảm chiều dữ liệu)
Đây là những thuật toán trong Unsupervised learning, giống như các thuật toán phân cụm, giảm chiều dữ liệu nhằm tìm ra cấu trúc vốn có của dữ liệu, giảm không gian tìm kiếm, tóm tắt hay mô tả dữ liệu sử dụng ít thông tin hơn.
Điều này giúp trực quan hóa dữ liệu tốt hơn hoặc đơn giản hóa dữ liệu mà sau đó, dữ liệu có thể được sử dụng trong các phương pháp học có giám sát.
2.9 Ensemble Algorithms (Thuật toán tập hợp)
Phương pháp tập hợp là phương pháp kết hợp các mô hình yếu hơn được huấn luyện độc lập và phần dự đoán của chúng sẽ được kết hợp theo cách nào đó để đưa ra dự đoán tổng thể
3. Tài liệu tham khảo
[1] Phân nhóm các thuật toán, machinelearningcoban.com
[2] Phân nhóm các thuật toán Machine Learning, nordiccoder.com
[3] 14 Different Types of Learning in Machine Learning, machinelearningmastery.com
[4] Types of Machine Learning Algorithms You Should Know, towardsdatascience.com